オブジェクト指向プログラミング(3)では,以下の項目に関して学ぶ.
C言語のプログラムでは,コンパイル時には判定できないエラー(実行時エラー)を起こす可能性がある文の実行に対して,その直後に条件文を用いてエラー検査を行う.この方法では,エラー検査のコードがプログラム内に散らばり,再利用を妨げる.これに対して,Javaは正常な処理とエラー処理を分離する例外(exception)という仕組みを持つ.例外とは,単純な実行時エラーだけでなく,ファイルの読み込みが終了したなどの特別な状況に陥ることも指す.
例外処理は,例外を送出する部分と,送出された例外を捕捉して決められた処理を実行する部分からなる.例外の発生と捕捉を含むプログラムを以下に示す.
public class Sample7 {
public static void main(String[] args) {
int numbers[] = new int[5];
numbers[0] = 3;
try {
numbers[10] = 0; // 実行時エラー発生
System.out.println(numbers[0]);
} catch (ArrayIndexOutOfBoundsException e) { // 例外を捕捉
System.out.println(e.toString());
}
System.out.println("Finish!");
}
}
ArrayIndexOutOfBoundsExceptionは,配列の添字が範囲を越えた際に送出される例外を表すクラスある.エラーが発生する可能性のあるコードをtryとcatchにはさむことで例外を捕捉し,catch節のブロックに例外の対処コードを記述する.ひとつのtryに対して,複数のcatch節を書くこともできる.捕捉された例外は,catchブロックの実行後に消滅する.
Sample7.javaのソースコードをコンパイルして実行すると,以下のようになる.
% java Sample7
java.lang.ArrayIndexOutOfBoundsException: 10
Finish!
実行例を見ると,例外の発生によりnumbers[0]の値を表示する文の実行がスキップされて,実行箇所がcatch節に移っていることがわかる.また,例外が発生しているにもかかわらず,例外対処コードの実行後にプログラムは正常に終了している.このように,try-catchブロックを用いることで,例外処理を簡単に分離できる.さらに,catch節を見てわかるように,例外の種類に応じて用意した例外クラスのインスタンス(e)に例外情報が格納される.このインスタンスはメソッドの引数のように受け取ることができる.例外処理コードでは,このインスタンスにアクセスすることで例外情報を取得する.
例外クラスは,大きくError系の例外とException系の例外に分けることができる.
Errorを祖先に持つクラス群にまとめられており,一般的にクラス名に“Error”を含む.代表的なものとして,OutOfMemoryError (メモリ不足), StackOverflowError (スタックオーバフロー)などがある.Exceptionを祖先に持つクラス群にまとめられており,一般的にクラス名に“Exception”を含む.代表的なものとして,InterruptedException (スレッドの中断), IOException (入出力処理エラーの発生),EOFException (ファイルの終わりに達した),FileNotFoundException (ファイルが見つからない),ArithmeticException (ゼロ除算などの算術エラーが発生),ClassCastException (不正な型への変換),ArrayIndexOutOfBoundsException (配列における範囲外の添字指定), StringIndexOutOfBoundsException (文字列型Stringにおける範囲外の添字指定),NullPointerException (nullインスタンスへのアクセス)などがある.Error系およびException系の例外クラスは,どちらもクラスThrowableの子孫である.よって,Throwableを使用することで,すべての例外を捕捉することが可能である.また,例外クラスの継承階層により,複数のサブクラスの例外をそれらの親クラスでまとめて捕捉することも可能である.
別の分類として,例外はチェック例外(checked exception)と非チェック例外(unchecked exception)に分けられる.チェック例外は,例外の対処コードが記述されているかどうかをコンパイル時に検査する.よって,開発者はtry-catchを必ず書かなければならない.一方,非チェック例外は,例外の対処コードが記述されているかどうかをコンパイラが検査しない.よって,開発者はtry-catchを書いても書かなくてもよい.クラスRuntimeExceptionあるいはクラスErrorの子孫クラスはすべて非チェック例外であり,その他の例外クラスはチェック例外である.
次に,例外に対する実行制御を見てみる.例外が発生すると,その時点でプログラム制御がtryブロックから脱出してcatch節に移る.このため,特定の文が実行されず,問題を引き起こすことがある.以下のソースコードでは,ファイルが存在しない,あるいは,ファイル読み込みに失敗することで例外が発生した場合,そのファイルをクローズする処理が実行されない.
try {
FileReader reader = new FileReader("data.txt");
reader.read();
reader.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
finally文を用いることで,例外の発生に関わらず,tryブロック内から脱出する前に必ず実行してほしい文を指定することができる.たとえば,以下のコードにおいて,ファイルをクローズは例外の発生に関係なく必ず実行される.
FileReader reader = null;
try {
reader = new FileReader("data.txt");
reader.read();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (reader != null) {
try {
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
上記のソースコードは,try-with-resources 文を利用することで,以下のように簡潔に記述することができる.
try (FileReader reader = new FileReader("data.txt")) {
reader.read();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
try-with-resources 文で宣言されたリソースは,try 文が正常に終了したかどうかにかかわらず,必ずクローズされる.
これまで述べたように,例外が発生した文を含むメソッド内で捕捉した例外に対処する場合はtry-catchを用いる.これに対して,捕捉した例外をそのメソッド内で処理せず,別のメソッド内で対処したい場合には,予約語throwsを用いる.throwsは,それが付与されたメソッド内で例外が発生する可能性があることを指しており,捕捉した例外はそのままメソッドの呼び出し側に戻される.このような例外の引き渡しの仕組みを提供することで,メソッドの戻り値を使用しなくとも,メソッド呼び出し側に例外の情報を伝達することができる.また,コンストラクタにおいても,インスタンスを生成する側に例外情報を伝達することが可能となる.throwsを用いた例を以下に示す.
void read() throws FileNotFountException {
FileReader reader = new FileReader("data.txt");
}
プログラムで処理する仕事をタスク(task)という.スレッド(thread)とは,タスクを処理する実体(実行環境)である.通常のプログラムにおいては,たとえ制御が分岐や繰り返しを含んでいたとしても,処理の流れは1本の糸のように実行される.つまり,一つのスレッドが複数のタスクを順番に実行する.このようなプログラムを,シングルスレッド・プログラム(single thread program)という.
これに対して,複数のスレッドを用意して,複数のタスクを並行に実行するプログラムのことを,マルチスレッド・プログラム(multi-thread program)という.Javaはマルチスレッドプログラムを扱うことができる.たとえば,画面に表示するスレッドと,マウス操作を処理するスレッドを分離することで,表示中でもマウス操作が可能となる.あるいは,サーバにおいて,複数のスレッドが別々にセッションを管理することで,それぞれのセッションが独立して処理を実行することができる.ただし,マルチスレッドとは複数の処理の流れを同時に実行するように見せかけるだけであり,複数のCPUがない限り複数のスレッドが同時に実行できるわけではない.
通常,プログラムを起動した際に,1つのメインスレッドが生成され,それが実行される.ただし,GUIプログラムでは,イベントディスパッチスレッドが自動的に生成され,メインスレッドと並行に実行される.
このようにあらかじめ用意されているスレッドだけでなく,Javaはプログラマが新しいスレッドを作成できる仕組みを提供している.メインスレッド以外に,新たにスレッドを作成するには,次の2つの方法がある.
Threadを拡張する.Runnableを実装する.ここでは,まずクラスThreadを拡張する方法を示す.Threadは,スレッドとしての基本的な機能をクラス内に備えている.そこで,Threadを継承して,メソッドrun()を再定義することで,独自のスレッドを定義することができる.新たなスレッドを定義し,そのスレッドを起動するソースコードを以下に示す.
public class Sample8 {
public static void main(String[] args) {
ThreadA thread = new ThreadA(); // スレッドの生成
thread.start(); // スレッドの実行を開始
for (int i = 0; i < 10; i++) {
System.out.println("main thread: " + i);
}
}
}
class ThreadA extends Thread { // Threadを継承
@Override
public void run() {
for (int i = 0; i < 10; i++) {
System.out.println("my thread: " + i);
}
}
}
Threadを拡張したクラスThreadAのインスタンスthreadを生成し,Threadから引き継いだメソッドstart()を呼び出すことで,新たなスレッドが起動される.その後,自動的にThreadAのメソッドrun()が呼び出される.メソッドrun()の実行が終了すると,スレッドは消滅する.
Sample8.javaのソースコードをコンパイルして実行すると,以下のようになる(実際のスレッドの実行順序は,実行ごとに異なる可能性がある).
% java Sample8
main thread: 0
my thread:0
my thread: 1
main thread: 1
...
このように,Threadを拡張することで簡単に新しいスレッドを定義することができる.
一方で,Javaでは単一継承しかできないため,この方法では新しいスレッドの定義ができないことがある.このような場合には,インタフェースRunnableに対してメソッドrun()を実装したクラスを作成する.このクラスをThreadに関連付けることで,新しいスレッドを起動することができる.Runnableを用いたソースコードを以下に示す.
public class Sample9 {
public static void main(String[] args) {
Thread thread = new Thread(new ThreadB()); // Threadの生成と関連づけ
thread.start(); // スレッドの実行を開始
for (int i = 0; i < 10; i++) {
System.out.println("main thread: " + i);
}
}
}
class ThreadB implements Runnable { // Threadを実装
public void run() {
for (int i = 0; i < 10; i++) {
System.out.println("my thread: " + i);
}
}
}
まずRunnableを実装したクラスThreadBのインスタンスを生成し,そのインスタンスを引数としてThreadのインスタンスを生成する.Threadのメソッドstart()を呼び出すことで,新たにスレッドが起動される.その後,自動的にThreadBのメソッドrun()が呼び出される.Sample9.javaのソースコードをコンパイルして実行すると,Sample8.javaのときと同様の結果が得られる.
ここでは,スレッドを操作するために,クラスThreadが提供するメソッドをいくつか紹介する.
メインスレッドは暗黙的に実行されるため,スレッドを保持する変数が明示的に存在しない.よって,現在実行中のスレッドに関する情報を知りたい場合には,以下のようにコードを記述する,
Thread thread = Thread.currentThread();
Threadが提供するメソッドsleep()を使用することで,実行中のスレッドを一時停止させることができる.たとえば,クラスSample15のメソッドmain()の内部にこのコードを記述すると,main()を実行中のスレッドが一時的に停止される.一方,クラスThreadAのメソッドrun()の内部にこのコードを記述すると,run()を実行中のスレッドが一時的に停止される.sleep()の引数には,ミリ秒単位で数値を指定する.
Thread.sleep(1000); // 現在実行中のスレッドを1000ミリ秒停止
sleep()により一時停止しているスレッドに割り込みたい場合は,メソッドinterrupt()を使用する.
MyThread thread = new MyThread();
thread.start();
...
if (thread.isInterrupted() == false) { // 割り込み処理中かどうかを検査
thread.interrupt(); // スレッドthreadに割り込む
}
あるスレッドがsleep()を呼び出すことで一時停止中になった状態で,別のスレッドがメソッドinterrupt()を呼び出すことで割り込んだ場合,sleep()はInterruptedException>例外を発生させる.つまり,一時停止中のスレッドは,sleep()に関するInterruptedException例外を捕捉することで,別のスレッドからの割り込みを検出することができる.
プログラムによっては,複数のスレッドを協調動作させたいことがある.このような場合,あるスレッドが別のスレッドの実行の終了を待つ必要がある.これに対して,Threadはメソッドjoin()を提供している.メソッドjoin()は次のように使用する.
MyThread thread = new MyThread();
thread.start();
...
try {
thread.join(); // スレッドthreadの終了を待つ
} catch (InterruptedException e) { }
スレッドが生存しているかどうかを確認するためにはメソッドisAlive(),スレッドの優先順位を設定するにはメソッドsetPriority(),優先順位を取得するためにはgetPriproty()を使用する.ただし,優先順位はあくまでもJava処理系において,優先順位の高いスレッドの実行を優先させるように努力することを示しているだけである.実際の実行順序はOSなどに依存し,優先順位は保証されていない.
複数のスレッドが独立して動作している場合は,特にスレッド間の関係を考える必要はない.しかし,複数のスレッドが同じデータを読み書きしたり,同じリソースを使用したりする場合,問題が発生する.たとえば,以下に示すメソッドdeposit()で実装した預金処理を考えてみる.
class Account {
private int balance;
Account(int bal) {
balance = bal;
}
void deposit(int money) {
int bal = balance; // 預金残高を取得
bal = bal + money; // 入金額を加算
balance = bal; // 預金残高を設定
}
}
このメソッドでは,まず,預金残高を格納するフィールドbalanceの値を読み込んで変数balに代入する.次に,balの値に入金額moneyを加算し,フィールドbalanceに値を書き戻す.
いま,スレッドAがこのメソッドを呼び出し,現在の預金残高balanceの値を読み込んだ瞬間を考える.スレッドAが入金額を加算し,その値を書き戻すまで,別のスレッドBがこのメソッドを実行しなければ問題は発生しない.しかし,スレッドAが入金額を加算中に,スレッドBが預金残高を読み込むと,その値はスレッドAにより入金額が加算される前の預金残高を指している.この場合,スレッドBの実行結果がスレッドAの実行結果を打ち消すことになる(逆の場合もあり得る).たとえば,預金残高1000円に対してこのような状況が発生すると,スレッドAとスレッドBにより預金残高にそれぞれ100円ずつ入金額が加算されても,最終的な預金残高は1100円(1000円+100円)にしかならないことがある.
複数のスレッドが共有データにアクセスする場合に問題が発生するソースコードを以下に示す.
Sample10.java
public class Sample10 {
public static void main(String[] args) {
Account10 acc = new Account10(1000);
Client10 c1 = new Client10(acc);
Client10 c2 = new Client101(acc);
c1.start();
c2.start();
}
}
class Client extends Thread {
private Account10 account;
Client10(Account10 acc) {
account = acc;
}
public void run() {
account.deposit(100);
}
}
class Account10 {
private int balance;
Account10(int bal) {
balance = bal;
}
void deposit(int money) {
int bal = balance;
bal = bal + money;
try {
Thread.sleep(1000); // 時間かせぎ
} catch (InterruptedException e) { }
balance = bal;
System.out.println("Current balance = " + balance);
}
}
Sample10.java のソースコードをコンパイルして実行すると,以下のようになる(実際のスレッドの実行順序は異なる可能性がある).
% java Sample10
Current balance = 1100
Current balance = 1100
2つのスレッドがメソッドdeposit()をそれぞれ1回ずつ呼び出しているため,最終的な残高は1200円になるはずである.それにもかかわらず,実行結果を見ると,残高は1100円となっている.ここで,Sample10.javaでは,2つのスレッドが同時にメソッドdeposit()を呼び出すように,スレッドを一時的に停止させるコードを意図的に挿入している.
残高を正しく計算するためには,スレッドAの実行が終了してからスレッドBの実行を開始すればよい.つまり,スレッドAの実行にスレッドBの実行が割り込めない(差し込まれない)ようにしなけばならない.このような実行を排他制御(mutual exclusion control)と呼ぶ.Javaでは,メソッドの宣言部やブロックにsynchronizedを付与する同期化(synchronization)で実現している.以下のように,メソッドの宣言部にsynchronizedを記述することで,このメソッドの処理は同時に一つのスレッドしか実行できなくなる.
synchronized public void deposit(int money) { ...}
共有データにアクセスするメソッドの同期化を行ったソースコードを以下に示す.
public class Sample11 {
public static void main(String[] args) {
Account11 acc = new Account11(1000);
Client11 c1 = new Client11(acc);
Client11 c2 = new Client11(acc);
c1.start();
c2.start();
}
}
class Client11 extends Thread {
private Account11 account;
Client11(Account11 acc) {
account = acc;
}
@Override
public void run() {
account.deposit(100);
}
}
class Account11 {
private int balance;
Account12(int bal) {
balance = bal;
}
synchronized void deposit(int money) { // メソッドの同期化
int bal = balance;
bal = bal + money;
try {
Thread.sleep(1000);
} catch (InterruptedException e) { }
balance = bal;
System.out.println("Current balance = " + balance);
}
}
Sample11.javaのソースコードをコンパイルして実行すると,以下のようになる.
% java Sample11
Current balance = 1100
Current balance = 1200
スレッドのモニタ(スレッドのブロックとアンブロックを実行するインスタンス)と,メソッドや変数のロック(スレッドに実行権を与えるための鍵)という仕組みで,これを実現している.同期化メソッド(synchronized宣言されたメソッド)が呼び出された場合,そのメソッドを含むインスタンスに自動的にロックがかけられる.ロックのかかっているインスタンスに対しては,別のスレッドが同期化メソッドを実行できず,ロックが解除(アンロック)されるまで,別のスレッドは待たされることになる.ロックをかけたスレッドの処理が終了すると,自動的にロックは解除される.
ここで注意しなければならないこととして,ロックの対象はメソッドではなく,インスタンスであることがあげられる.あるスレッドが同期化メソッドを実行しているとき,他のスレッドはそのインスタンスのすべての同期化メソッドを実行できない.同期化されていないメソッドは常に実行可能である.また,あるインスタンスにロックがかかっている状態でも,別のインスタンスの同期化メソッドは実行可能である.もし同期化メソッドがインスタンスメソッドでなくクラスメソッドであった場合は,ロックはインスタンスではなくクラスにかけられる.
同期化対象をメソッド全体ではなく,メソッド内の一部としたい場合には,次のようにsynchronized文を使用する.
synchronized (式) { ... }
ロックによる排他制御は,デッドロックを引き起こす危険性があるため,十分に注意してプログラムを作成する必要がある.また,複数のスレッドが処理を実行している場合,それらのスレッドを任意の時点で協調させたいことがある.Javaでは,これをスレッド間通信で実現している.スレッド間通信に必要な処理は,クラスObjectのメソッドwait(),notify(), notifyAll()で提供されている.あるインスタンスのwait()を呼び出すと,そのインスタンスにロックをかけていたスレッドは,ロックを解除して待機状態に移る.待機状態にあるインスタンスのメソッドnotify()が呼び出されると,待機中のスレッドのうちどれか一つが実行可能状態になる.notify()の代わりにメソッドnotifyAll()が呼び出されると,待機状態にあるインスタンスにおける待機中のすべてのスレッドが実行可能状態に移る.実行中のスレッドのロックが解除されると,実行可能状態のスレッドが再開される.
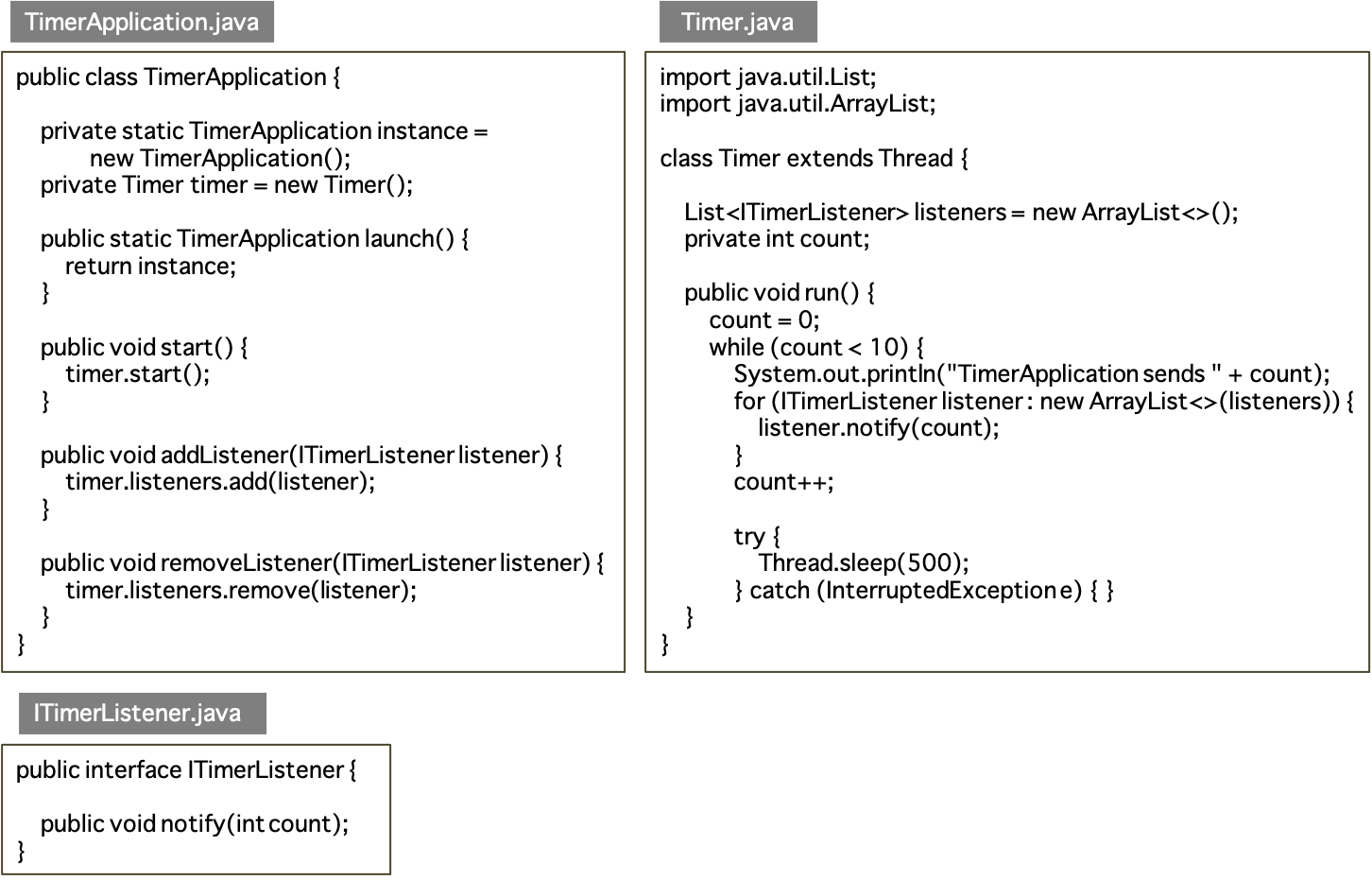
クラス図を記述せよ.
Exercise31 と Exercise32 を実行した際の画面出力をそれぞれ求めよ.

データを生産(送信)する Producer とデータを消費(受信)する Consumer が異なるスレッドで動作している場合を考える.生産者と消費者は,共有するチャネル(Channel)を利用して,データの受け渡しを行う.ここでは,同時にチャネルに置けるデータの上限数(バッファサイズ)を N とする.Producer と Consumer の動作における制約は以下のようになる.
Producer は生産したデータを格納するput)ことができる.ただし,すでにN個のデータがチャネルに格納されている場合は,N個より少なくなるまで待つ.Consumerは.チャネルに格納されているデータを取る(

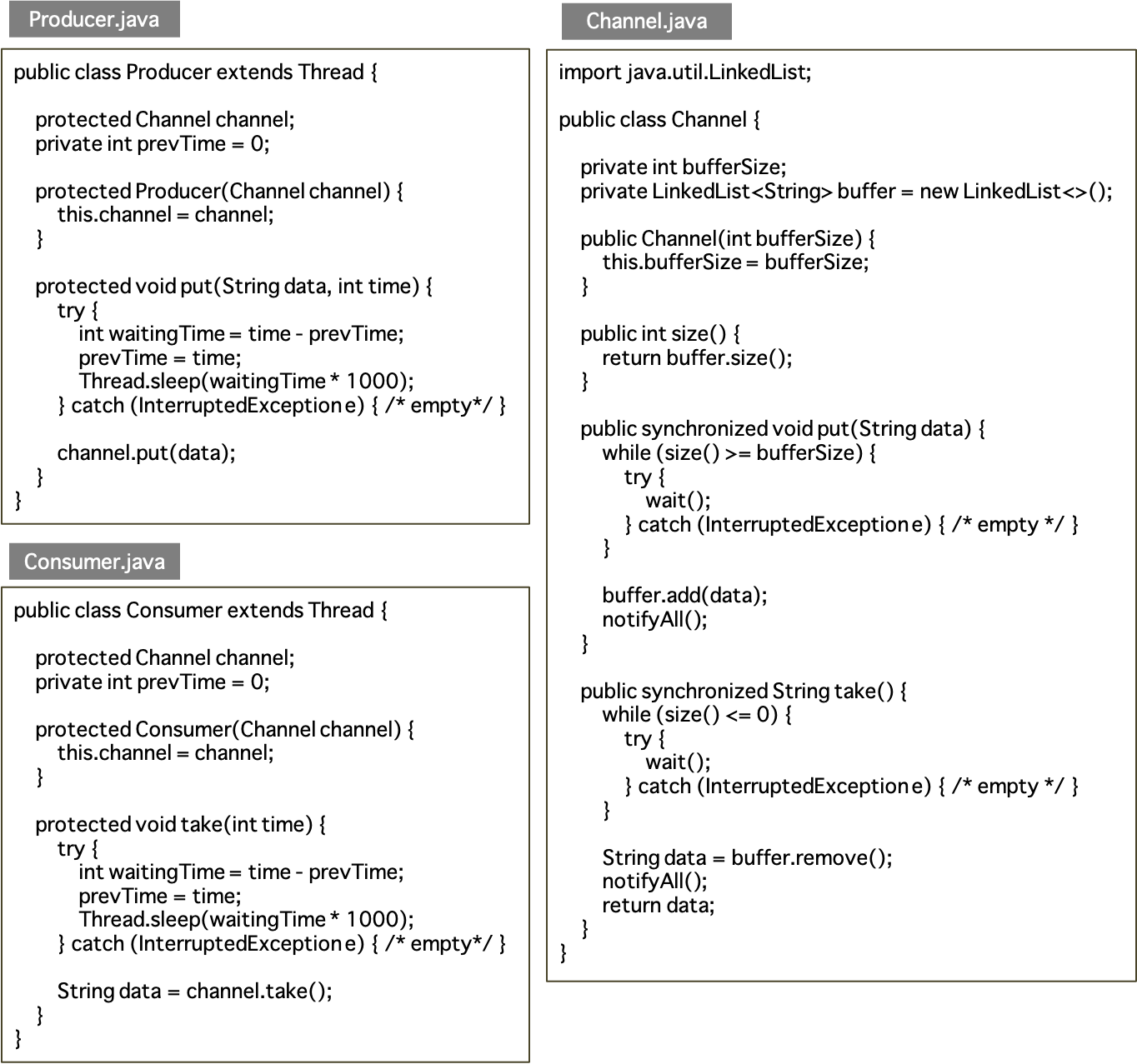
上記のソースコードは,大きさ1のバッファを持つ Channel のインスタンスに対して,Producer のインスタンスがデータ(String型)を格納する.これに対して,Consumer のインスタンスが,バッファからデータを取り出す.ProducerとConsumerは異なるスレッドで別々に動作しており,それらがデータを共有しているため,協調動作が必要である.
もしデータがまだバッファに残っている状態において,Producer がデータをさらに格納しようとすると,wait() の呼び出しにより Producer に割り当てられたスレッドの実行が待たされる.この状態で Consumer がデータを取り出すと,notifyAll() の呼び出しにより Producer に割り当てられたスレッドが再開される.また,もしデータがまだバッファに存在しない状態において,Consumer がデータを取り出そうとすると,wait() の呼び出しにより code>Consumer に割り当てられたスレッドの実行が待たされる.この状態で Producer がデータ格納すると,notifyAll() の呼び出しにより Consumer に割り当てられたスレッドが再開される.このようにして,ProducerとConsumerがデータの共有を通して協調動作している.
上記に述べたように,メソッド put() とメソッド take() のデータへのアクセスが協調動作していることを確認せよ.
ProducerA と ConsumerA を利用した Exercise33 を実行した際のシーケンス図は以下のようになる.
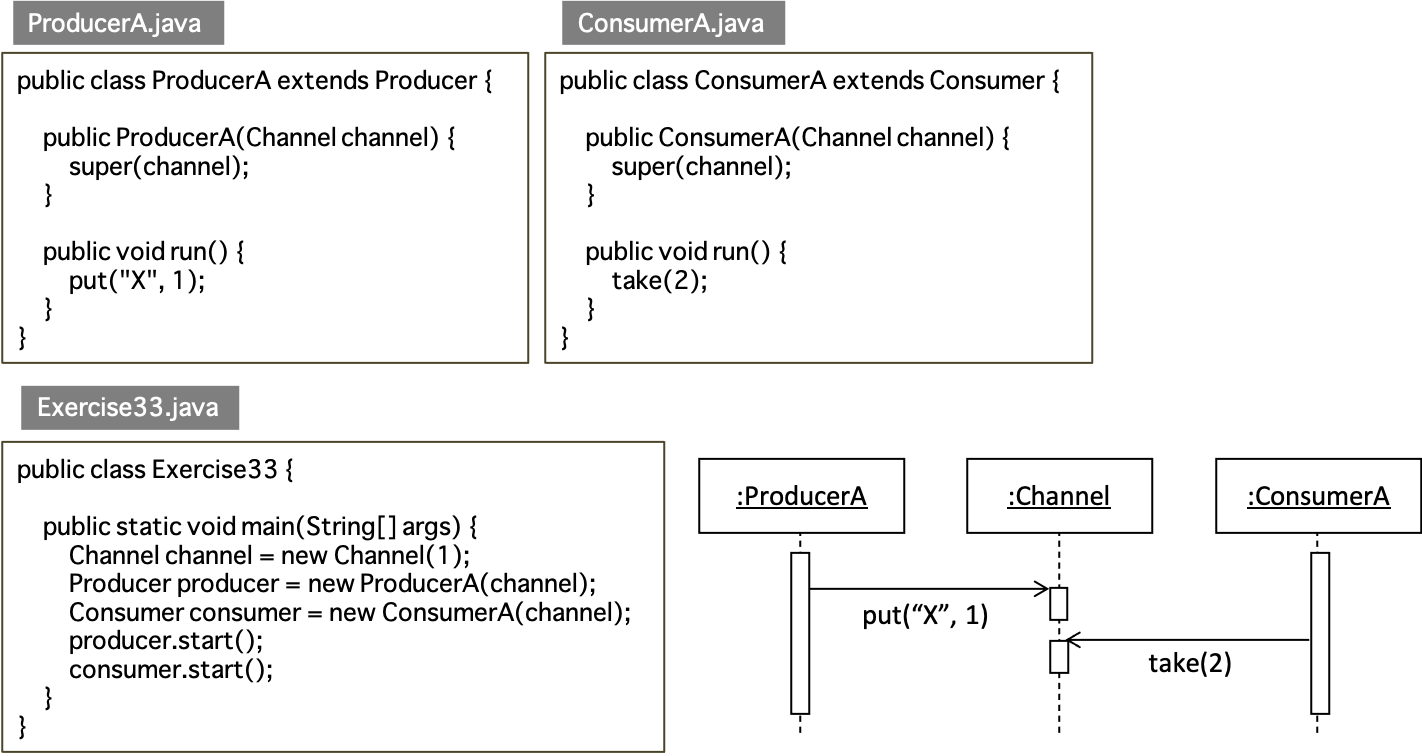
ProducerB と ConsumerB を利用した Exercise34 を実行した際のシーケンス図を記述せよ.

大きさ1のバッファを利用した際でも,複数のデータの受け渡しは成功する.
ProducerC と ConsumerC を利用した Exercise35 を実行した際のシーケンス図を記述せよ.

ProducerD と ConsumerD を利用した Exercise36 を実行した際のシーケンス図を記述せよ.

ProducerE と ConsumerE を利用した Exercise37 を実行した際のシーケンス図を記述せよ.

Copyright 2025 Katsuhisa Maruyama. All rights reserved.