 Reengineering Software Evolution Technology
Reengineering Software Evolution Technology
ソフトウェア進化技術の実践に関する調査研究
コードクローンパターン
コードクローン(code clone)とは,ソースコードのコピー&ペーストによって作られた(あるいは,作られたように見える)コードの断片を指す[17].これは,重複コード(duplicated code)とも呼ばれる.一般的に,コードクローンの存在がソフトウェア保守を難しくするといわれており,FowlerやBeckもリファクタリングにおけるコードの悪臭のひとつであると指摘している[8].
このような背景を受け,重複コードを発見するための2つのパターンがOORP[7]の8章に紹介されている.8.1では,コードを機械的に比較しよう / Compare Code Mechanically (OORP パターン8.1)が紹介されている.大規模なプログラムのコードを手動で調べ上げ,コードの重複を発見することは現実的でない.このパターンでは,ソースコードのテキストを行ベースで比較するスクリプトを利用することを奨励している.次に,8.2 では,散布図(ドットプロット)を用いてコードを視覚化しよう / Visualize Code as Dotplots (OORP パターン8.2)が紹介されている.散布図とは,2つのソースコードファイルの各行をX軸とY軸に並べ,重複する行の位置にドットを表示した行列を指す.行列内に現れるドットの形状に応じて,4つの解釈が提案されている.
ここでは,OORPの重複コード発見パターンに追加する形で,コードクローンに関する5つのパターンを紹介する.
- パターン3.1 着目すべき特徴を絞って散布図を分析しよう
- パターン3.2 類似したファイル群を抽出しよう
- パターン3.3 プロダクト中の類似部分を探そう
- パターン3.4 プロダクト間にまたがる類似部分を探そう
- パターン3.5 重複部分の一貫性を維持しよう
パターン 3.1
着目すべき特徴を絞って散布図を分析しよう
Focus on Particular Dotplots
散布図を解釈し,重複コードの存在によって生じるソースコードの問題点やその解決策を分析したい.
問題
- 散布図を使って重複コードを分析する際に散布図のどの部分に着目すればいいのかわからない.
- 分析者がコードクローンの専門家でない場合,散布図を見てもソースコードのどの部分に問題があるのか判断が難しい.
- 重複コードがどのような経緯で混入したか,その重複コードに対してどのような処置をすればよいのか,専門的な知識なしには分析ができない.
解法
- 散布図を分析する際,着目すべき部分の特徴として,次に示す3つの戦略を用いる.
戦略1: 対角線に着目(図3.1)
戦略2: 分断された対角線に着目(図3.2)
戦略3: 破線・点線に着目(図3.3)
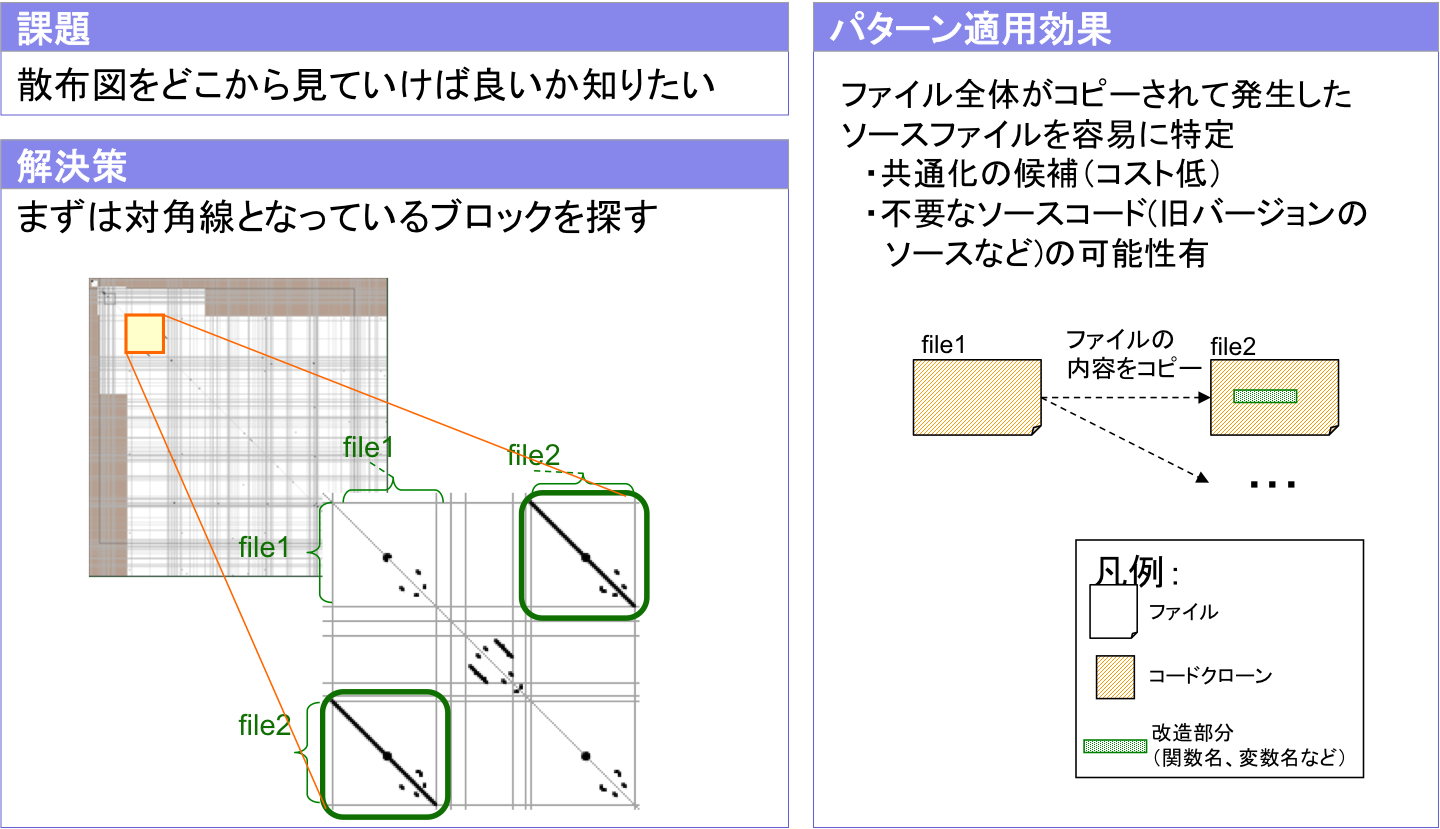
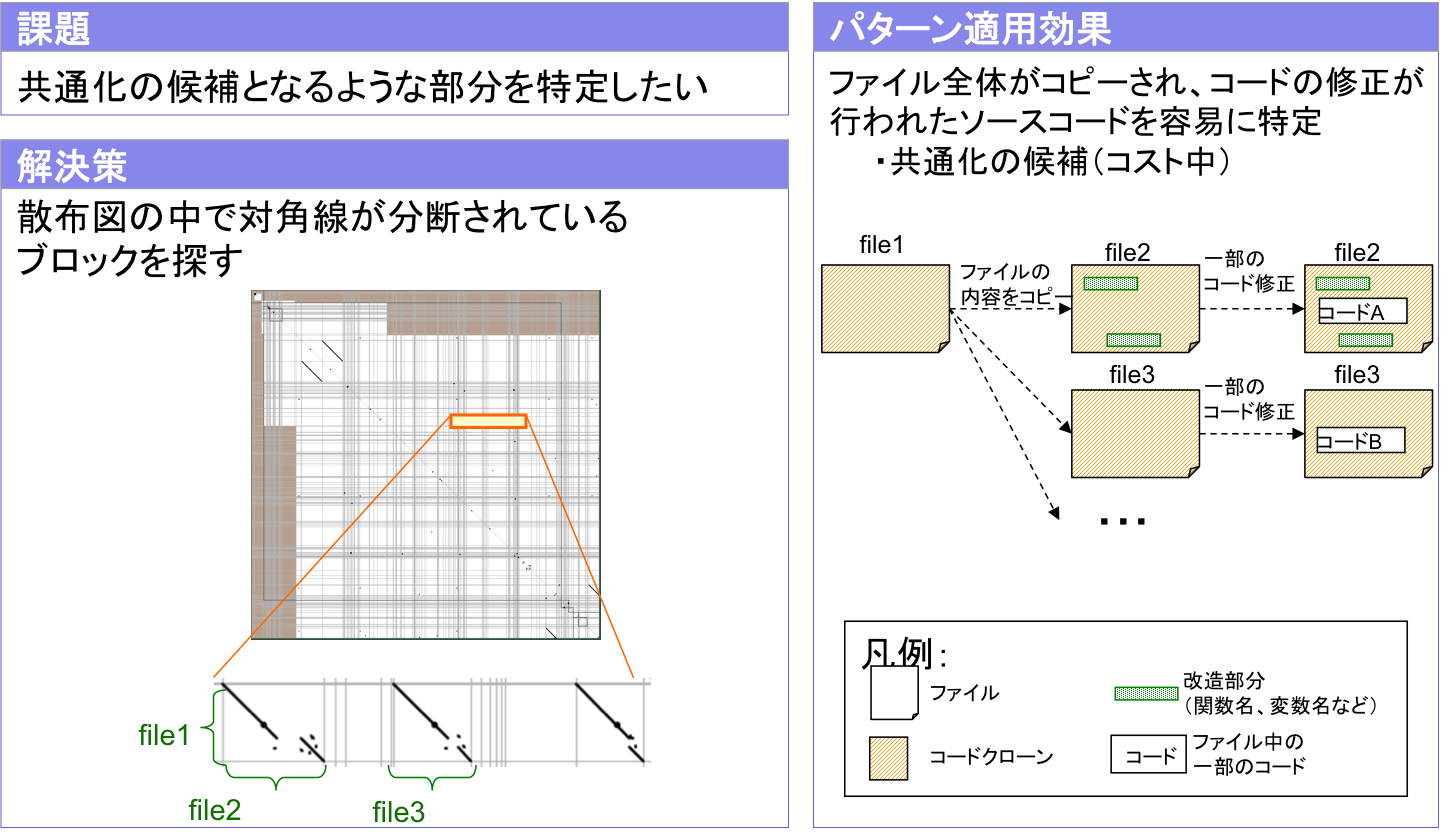
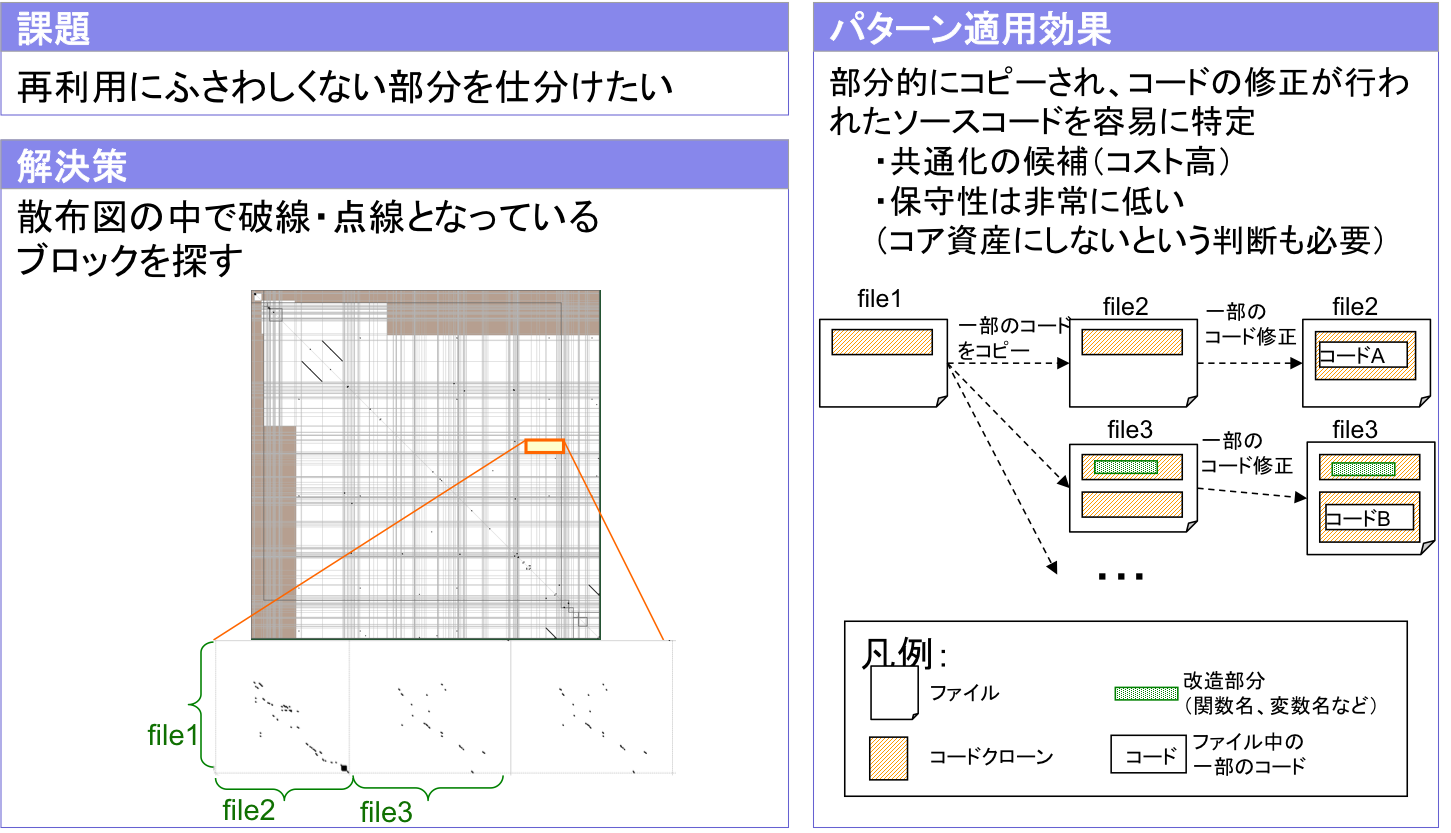
トレードオフ
-利点
- どういう経緯で発生した重複コードであるか,リファクタリング適用の難しさ等について,コードクローンに関する専門知識がなくても分析することができる.
- パターンを特定するための定量的な尺度がないため,分析結果が分析者の主観に依存する可能性がある.
- ソースコードが大規模である場合,描画領域のサイズの制約によって散布図の詳細を表示しきれず,特徴を発見できない可能性がある.
関連するパターン
重複コードを,散布図を利用して解釈する方法は,OORPの散布図を用いてコードを視覚化しよう (OORP パターン8.2) で示されている.本パターンは,散布図の解釈方法を詳細に示したものである.
パターン 3.2
類似したファイル群を抽出しよう
Extract Similar File Groups
大規模なソースコードの重複コードを,散布図を使って分析したい.
問題
- 分析対象のコードが大規模である場合,散布図上に詳細を表示できない.
- 分析対象ソースコードが大規模である場合,図3.4のように散布図の詳細部分を表示できず,「着目すべき特徴を絞って散布図を分析する」で示した特徴を散布図から発見することができない.この問題については,OORPの散布図を用いてコードを視覚化しよう (OORP パターン8.2) でも,“The screen size limits the amount of information that can be visualized”と指摘されている.
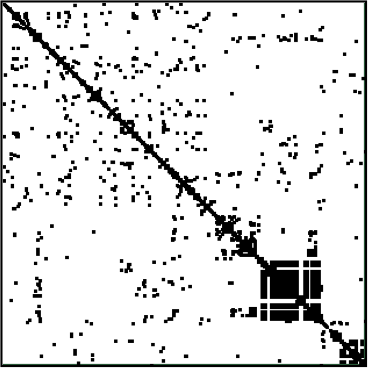
(あるOSSのソースコードの散布図)
解法
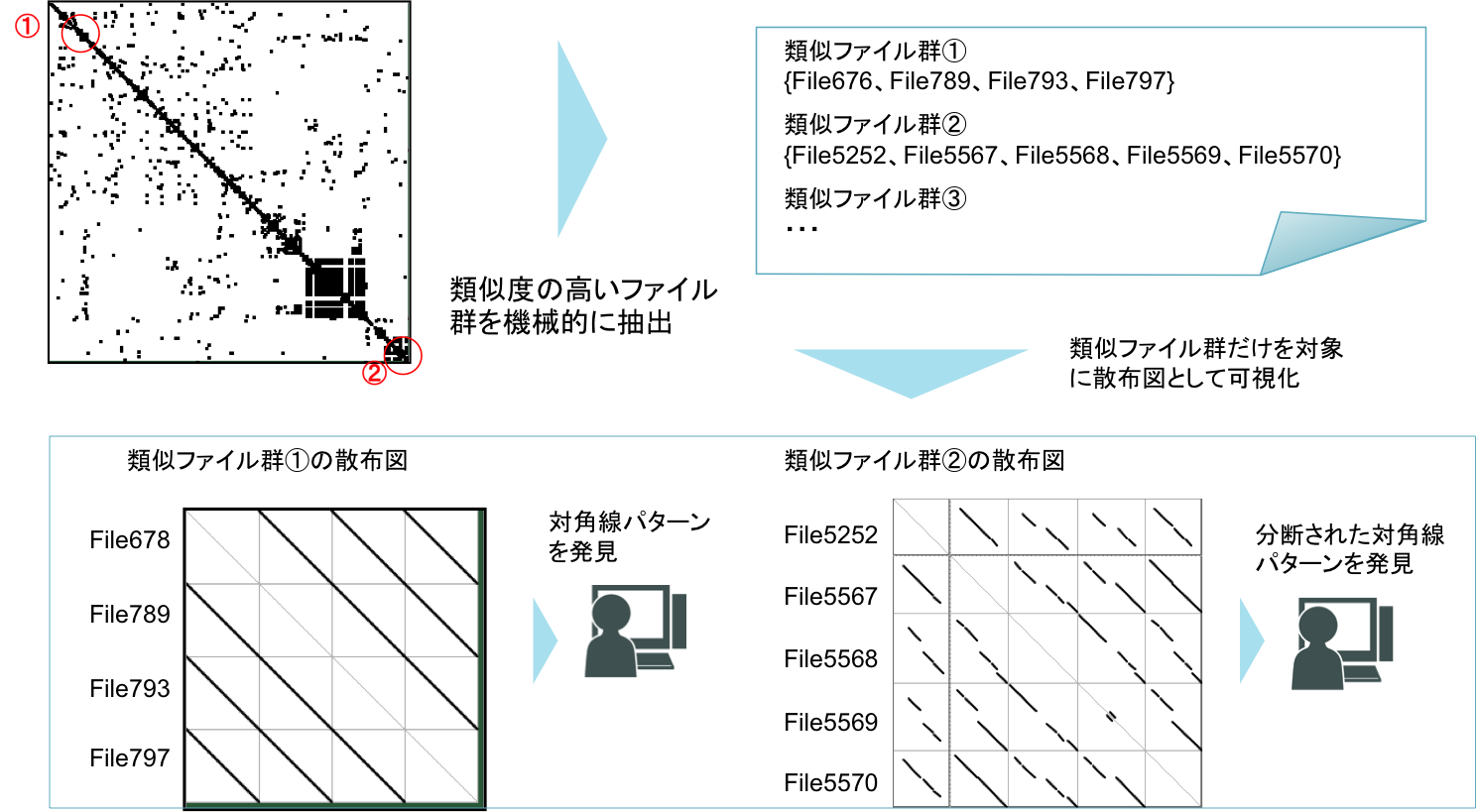
- 類似度の高いファイル群を機械的に抽出する.
- 分析対象ソースコード全体を散布図として表示するのではなく,詳細な分析が必要なファイル群に絞込みを行った上で分析を行う.
- 互いに重複箇所の多いようなファイル群を抽出することで,互いに重複箇所を持たないようなファイルを除外することができる.
- 絞込みを行った上で「着目すべき特徴を絞って散布図を分析する」を適用することで,散布図の特徴に着目した分析が可能となる.図3.5は,ファイルの類似度に基づいて類似ファイル群を抽出し,「着目すべき特徴を絞って散布図を分析する」を適用する流れを示したものである.
- コードクローン分析の目的によって抽出の粒度をディレクトリ,メソッドなどとすることも可能である.サブシステムレベルでの重複コードを特定したい場合には抽出の粒度をディレクトリにする,などが考えられる.
トレードオフ
-利点
- 散布図として表示するファイル数が少なくなるため,コードクローンの分布状況を詳細に表示することができ,散布図上での分析が容易になる.
- 散布図描画ツールのスケーラビリティのハードルが低下する.
- 類似ファイル群のみの可視化になるため全体を俯瞰した分析ができない.
- 類似度の定義や類似度の閾値によって抽出される類似ファイル群が異なるため,コードクローン分析の目的によってこれらを決定する必要がある.
パターン 3.3
プロダクト中の類似部分を探そう
Identify Similar Parts Within a Product
レガシーソフトウェアの大規模な改修をする計画がある.その際,改修にあわせ共通化すべき部分を特定し,集約したい.改修にあわせることで,網羅的なテストを同時にできるため,共通化すべき部分の集約が受け入れられやすい.
問題
- 仕様書や設計書に記載された情報だけでは,類似性した部分を判断しづらい.また,それら文書の一部が欠如している,もしくは古いという問題がある場合もある.
解法
- ディレクトリなどの単位でソースコードの類似性を計測する.
- ソースコードを分析することで,仕様書や設計書の一部が欠落している,もしくは古いという問題があっても回避することができる.
- 類似性の計測には,CCFinderなどのクローン検出ツールを使うことができる.最小一致トークン数は100トークンなど検出ツールのデフォルト値よりは大きめに設定するほうが,大規模なソースコードを対象とした場合であっても高速に検出できる.
トレードオフ
-利点
- 仕様書や設計書に問題があっても,共通化すべき部分を判断できる.
- ソースコードの類似性のみで共通化を判断すると,将来の保守において独立して大規模な改修が行われるなどして,理解容易性が下がる可能性がある.
関連するパターン
類似部分がプロダクト間にまたがる場合は,プロダクト間にまたがる類似部分を探そう (パターン3.4) の適用を検討する必要がある.また, 重複コードを発見するためには,OORPのコードを機械的に比較しよう (OORP パターン8.1)と散布図を用いてコードを視覚化しよう (OORP パターン8.2)が利用できる.発見した類似部分は,重複部分の一貫性を維持しよう (パターン3.5)で管理すべきである.
パターン 3.4
プロダクト間にまたがる類似部分を探そう
Identify Similar Parts Between Products
発注先が計画通りの流用を行っているか確認したい.
問題
- 別プロジェクトのソースコードを流用した開発を行っており,発注額の見積りに流用率を用いている.流用しない計画になっているにもかかわらず,ほとんど流用している場合がある.また,流用する計画になっていないにもかかわらず,流用後にほとんど改修している場合がある.
- 別プロジェクトのソースコードをどの程度流用しているかを,週報やLOC等の規模メトリクスで判断することは難しい.
解法
- 流用元のソースコードと流用先のソースコードの類似性を計測する.類似性の計測には,CCFinderなどのクローン検出ツールを使うことができる.
- それぞれのソースコード内のみに存在するコードクローンは検出する必要がないため,検出しないようにオプションを設定し,検出速度を向上させる.
- 最小一致トークン数は100トークンなど検出ツールのデフォルト値よりは大きめに設定するほうが,大規模なソースコードを対象とした場合であっても高速に検出できる.
トレードオフ
-利点
- 週報や規模メトリクスでは判断できない流用を特定できる.流用部分についても特定できる.
- ドメインに特化したコードクローン(データベース関連処理)が多く含まれる場合,それらコードクローンを流用と判断するおそれがある.
関連するパターン
類似部分がひとつのプロダクトに閉じているときは,プロダクト中の類似部分を探そう (パターン3.3)の適用を検討する必要がある.また, 重複コードを発見するためには,OORPのコードを機械的に比較しよう (OORP パターン8.1)と散布図を用いてコードを視覚化しよう (OORP パターン8.2)が利用できる.発見した類似部分は,重複部分の一貫性を維持しよう (パターン3.5)で管理すべきである.
パターン 3.5
重複部分の一貫性を維持しよう
Keep the Consistency of Duplicated Code
水平展開(類似部分の同時修正)が必要な部分を特定したい.
問題
- ソースコードが大規模になると,水平展開のコストが大きく,水平展開漏れが起きるおそれがある.
解法
- 改修を行ったコード片と保守対象のソースコード間のコードクローンを検出する.
- CCFinderなどのクローン検出ツールを使う場合は,最小一致トークン数は15トークンなど検出ツールのデフォルト値よりは小さめに設定する.
- Visual Studio Premium/Ultimateを用いている場合は,コードクローン検索機能を用いることができる.
- grepなどの文字列検索を合わせて用いることで,水平展開漏れを減らすことができる.
トレードオフ
-利点
- 仕様書や設計書に基づいた横展開では見落としてしまう場合を防ぐことができる.
- 必ずしも横展開が必要なコードが類似しているとは限らないため,過去に同時修正した部分の記録及び分析も必要である.
関連するパターン
類似部分の発見には,コードクローンパターンを利用できる.同時修正箇所が必ずしも類似しているとは限らないため,変更履歴を記録しよう (パターン4.1)や活動履歴を記録しよう (パターン4.2)の適用も検討する価値がある.
参考文献
- [1] M. M. Lehman, M. M., “Programs, Life Cycles, and Laws of Software Evolution”, Proc. IEEE, Vol.68, No. 9, pp. 1060-1076 (1980)
- [2] 大森隆行, 丸山勝久, 林晋平, 沢田篤史, “ソフトウェア進化研究の分類と動向”, コンピュータソフトウェア, Vol.29, No.3, pp.3-28 (2012)
- [3] W. M. Ulrich, P. H. Newcomb, “Information Systems Transformation: Architecture-Driven Modernization Case Studies”, Morgan Kaufmann (2010)
- [4] D. L. Parnas, “Software Aging”, Proc. ICSE'94, pp.279-287 (1994)
- [5] M. Jazayeri, “Species Evolve, Individuals Age”, Proc. IWPSE'05, 2005, pp.3-12 (2005)
- [6] E.J. Chikofsky, and J. H. Cross II, “Reverse Engineering and Design Recovery: A Taxonomy”, IEEE Software, Vol.7, No.1, pp.13-17 (1990)
- [7] S. Demeyer, S. Ducasse, O. Nierstrasz, “Object-Oriented Reengineering Patterns”, Morgan Kaufmann (2002)
(ダウンロード)
- [8] M. Fowler, “Refactoring: Improving the Design of Existing Code”, Addison-Wesley (1999)
(訳) 児玉公信, 平澤章, 友野晶夫, 梅沢真史, “リファクタリング”, ピアソンエデュケーション (2000)
- [9] パターンワーキンググループ, “ソフトウェアパターン入門”, ソフト・リサーチ・センター (2005)
- [10] P. Clements and L. Northrop, “Software Product Line: Practices and Patters”, Addison Wesley (2001)
- [11] K. Pohl, G. Böeckle, F. J. van der Linden, “Software Product Line Engineering: Foundations, Principles and Techniques”, Springer (2005)
(訳) 林好一, 吉村健太郎, 今関剛, “ソフトウェアプロダクトラインエンジニアリング ― ソフトウェア製品系列開発の基礎と概念から技法まで”, エスアイビーアクセス (2009)
- [12] J. McGregor, D. Muthig, K. Yoshimura, P. Jensen, “Successful Software Product Line Practices”, IEEE Software, Vol. 27, No. 3, pp.16–21 (2010)
- [13] K. C. Kang, S. G. Cohen, J. A. Hess, W. E. Novak, A. S. Peterson, “Feature-Oriented Domain Analysis (FODA) Feasibility Study”, CMU/SEI-90-TR-21 (1990)
- [14] K. C. Kang, V. Sugumaran, S. Park, “Applied Software Product Line Engineering”, Auerbach Publications (2010)
- [15] L. Gorchels, “The Product Manager's Handbook: The Complete Product Management Resource”, McGraw-Hill (2000)
- [16] 位野木万里, 杉本信秀, 深澤良彰, “ステークホルダの意思決定を支援するプロダクトライン再生シナリオの提案”, ソフトウェア工学の基礎ワークショップ(FOSE2008), pp.75–80 (2008)
- [17] 神谷年洋, 肥後芳樹, 吉田則裕, “コードクローン検出技術の展開”, コンピュータソフトウェア, Vol.28, No.3, pp.29–42 (2011)
- [18] J. Humble, D. Farley, “Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation”, Addison-Wesley Professional (2010)
(訳) 和智右桂, 高木正弘, “継続的デリバリー: 信頼できるソフトウェアリリースのためのビルド・テスト・デプロイメントの自動化”, アスキー・メディアワークス (2013)
- [19] P. M. Duvall, S. Matyas, A. Glover, “Continuous Integration: Improving Software Quality and Reducing Risk”, Addison-Wesley Professional (2007)
(訳) 大塚庸史, 丸山大輔, 岡本裕二, 亀村圭助, “継続的インテグレーション入門”, 日経BP社 (2009)
- [20] S. Thangthumachit, S. Hayashi, M. Saeki, “Understanding Source Code Differences by Separating Refactoring Effects”, Proc. APSEC'11, pp.339–347 (2011)
- [21] K. Herzig, A. Zeller, “The Impact of Tangled Code Changes”, Proc. MSR'13, pp. 121–130 (2013)
- [22] KDE TechBase, “Policies/Commit Policy”,
http://techbase.kde.org/Policies/Commit_Policy#Commit_complete_changesets
- [23] S. Appleton, B. Berczuk, “Software Configuration Management Patterns”, Addison-Wesley (2002)
- [24] S. Person, M. B. Dwyer, S. Elbaum, C. S. Păsăreanu, “Differential Symbolic Execution”, Proc. FSE'08, pp.226–237 (2008)
- [25] S. Lahiri and C. Hawblitzel, “Symdiff: A Language-Agnostic Semantic Diff Tool for Imperative Programs”, Proc. CAV’12, pp.712–717 (2012)
- [26] D. Jackson and D. A. Ladd, “Semantic Diff: A Tool for Summarizing the Effects of Modifications”, Proc. ICSM’94, pp. 243–252 (1994)
- [27] 角田雅照, 門田暁人, 松本健一, 押野智樹, “受託開発ソフトウェアの保守における作業効率の要因”, コンピュータソフトウェア, Vol.29, No.3, pp.157–163 (2012)
(訳) 児玉公信, 平澤章, 友野晶夫, 梅沢真史, “リファクタリング”, ピアソンエデュケーション (2000)
(訳) 林好一, 吉村健太郎, 今関剛, “ソフトウェアプロダクトラインエンジニアリング ― ソフトウェア製品系列開発の基礎と概念から技法まで”, エスアイビーアクセス (2009)
(訳) 和智右桂, 高木正弘, “継続的デリバリー: 信頼できるソフトウェアリリースのためのビルド・テスト・デプロイメントの自動化”, アスキー・メディアワークス (2013)
(訳) 大塚庸史, 丸山大輔, 岡本裕二, 亀村圭助, “継続的インテグレーション入門”, 日経BP社 (2009)
http://techbase.kde.org/Policies/Commit_Policy#Commit_complete_changesets